A window into the field of synthetic data generation for computer vision.

Source: Analytics India magazine
Earlier this year, I had a conversation with a manager at Cognizant heading the deep learning guild team. His team creates proofs-of-concept (pilot projects to demonstrate a business opportunity) using deep learning algorithms. One of the major challenges that he noticed his team faced was getting data for such POCs. Acquiring well-represented data specific to a problem was arduous. Additionally, utilizing real-world data to test if the system is providing the desired output was impossible in most cases as it imposed privacy-related issues. As we concluded the conversation, he indicated that a possible solution is to generate synthetic data and that his team had started looking into it. This conversation was my introduction to “Synthetic Data”.
In my two years of handling AI models, my focus on data fed into these models had never gone beyond the data augmentation process until then. Most often in the equation, AI system = model + data, we hold the data constant and proceed with tweaking parameters to improve the model performance. Andrew Ng recently posted on LinkedIn, that he is thinking of organizing competitions where we take a popular architecture and keep it constant, and ask teams to work with the data — an attempt to spur data-centric AI development.
“ The Architecture is not nearly as important most times as your dataset & having a high quality, representative dataset is always a good investment to make, probably more important than upgrading to the most recent detector in most cases. ” — Joseph Nelson, co-founder/ CEO @ Roboflow.
From my research, I realized that the lack of high-quality correctly annotated data was, in fact, the biggest challenge faced by AI teams around the world and it hampers deep learning from reaching its full potential.
I believe readers could use this article as a window into the field of synthetic data generation for computer vision (SDG-CV). There are lots of resources out there on SDG-CV but since the field recently gained popularity, there is a chance you might get lost. In this article, I attempt to pen down my understanding of synthetic data generation and its use-cases.
Synthetic data in computer vision tasks:
Synthetic Data is the data generated through computer programs. These programs can be generative deep learning algorithms (GAN’s, VAE’s, Autoregressive models) or CGI and gaming engines producing 3D simulations (Unreal, Unity, Blender to name a few). Synthetic data for computer vision can be RGB images, segmentation maps, depth images, stereo-pairs, LiDAR or Infrared images.

Figure1 : Synthetic RGB image, depth image, surface normal, semantic labels (Source: BlenderProc)
{kind=link}
To build robust, high performing deep learning models you need a bulk amount of annotated data. You’ll be surprised to know that in most cases these models don’t require realistic training images to perform well. They prefer diversity in data over photorealism, especially for object detection. However, segmentation tasks require a high degree of texture realism since segmentation models rely heavily on texture.
Below are a few examples that will demonstrate why the adoption of synthetic data is beneficial.
Examples of Synthetic data usage:
Say you are distressed by the amount of plastic bottles littering our planet every year. So you decide to train a robot to detect plastic bottles. Now, these bottles can crumple in thousands of different ways. Collecting pictures of bottles and annotating them is not just a tedious task but training your model with such a dataset isn’t going to cover all possible scenarios. Nevertheless, it’s too expensive. These bottles could be present on different terrains, under different lighting conditions, lying next to various other objects. The easier alternative would be to synthesize thousands of fake crumpled bottle images using any graphics engine — namely Unreal, Unity or Blender.
Let’s see a gnarly problem where synthetic data can come to the rescue — the example of self-driving cars trained to spot other cars on the road. It’s obvious that such systems have been trained on plenty of car images and it’s likely that they are extremely accurate at recognizing cars. But will it detect a flipped car? (This is an interesting example I got from Immersive Limit.) . It’s not practical to take thousands of images of flipped cars in the real world. However, by using any 3D rendering software we can synthesize as many flipped cars as we want with numerous variations.
How is synthetic data different from augmented Images?
When I initially started reading about synthetic data, a doubt that popped in my head was can’t the benefits of synthetic data be achieved through data augmentation. Well, here’s the answer to that.
Data Augmentation is a technique extensively used by DL and CV engineers to modify real data by rotating the image a few degrees, zooming in a bit or flipping the image. This technique creates variations of existing images in the dataset and can be viewed as a cheap alternative to generate more labelled data.
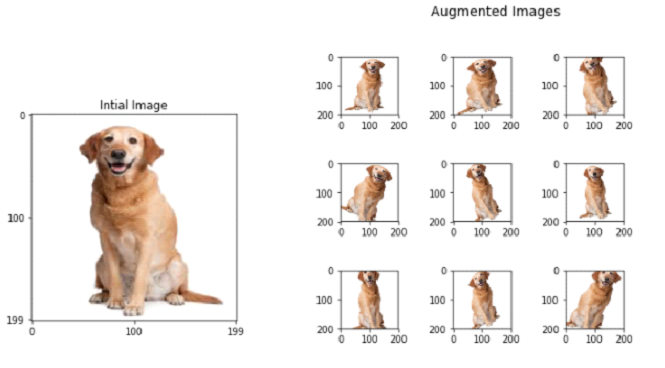

Figure (2a): Original input image. Figure(2b): Augmented images of the dog. Figure(2c): Target object-Dog on a different background. Source for Fig (2a) & (2b): Towards Data Science, Source for Fig (2c): Google Images.
{kind=link}
But what if our target object appears on different backgrounds, under different lighting conditions or in different contexts as shown in Figure(2c).
In such cases, synthetic data has the upper hand. Another example is, say you’re training a drone system to monitor the maintenance of a golf course. Your training data in this case are images of grass turfs and data augmentation can barely be of any use. Additionally, on a given day the lighting can be different depending on the weather and the time of the day. Using 3D-scene rendering software you can simulate the virtual golf courses and extract training images. It’s definitely not as easy as it sounds but it’s a one-time investment and saves you a lot of money and time in the future.
Generating synthetic data:
As mentioned earlier, Synthetic data can be generated by two methods:
1.Deep learning-based methods
There are two approaches that can be taken under this method :
a) Using Generative Adversarial Networks: In GAN model, we create a generative model that takes a random sample data and produces synthetic data that closely resembles the authentic data. Discriminator compares this synthetically generated data with a real dataset based on conditions that are set before.
b) Using Variational Autoencoder: In VAE model, the encoder compresses the real dataset into a compact form and transmits it to the decoder. The decoder then generates an output which is a representation of the real dataset. The system is trained by optimizing the correlation between input and output data.
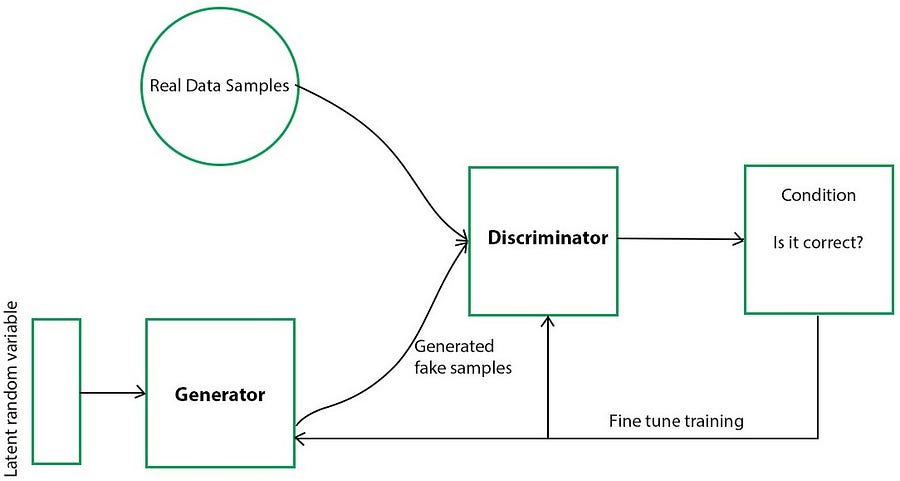
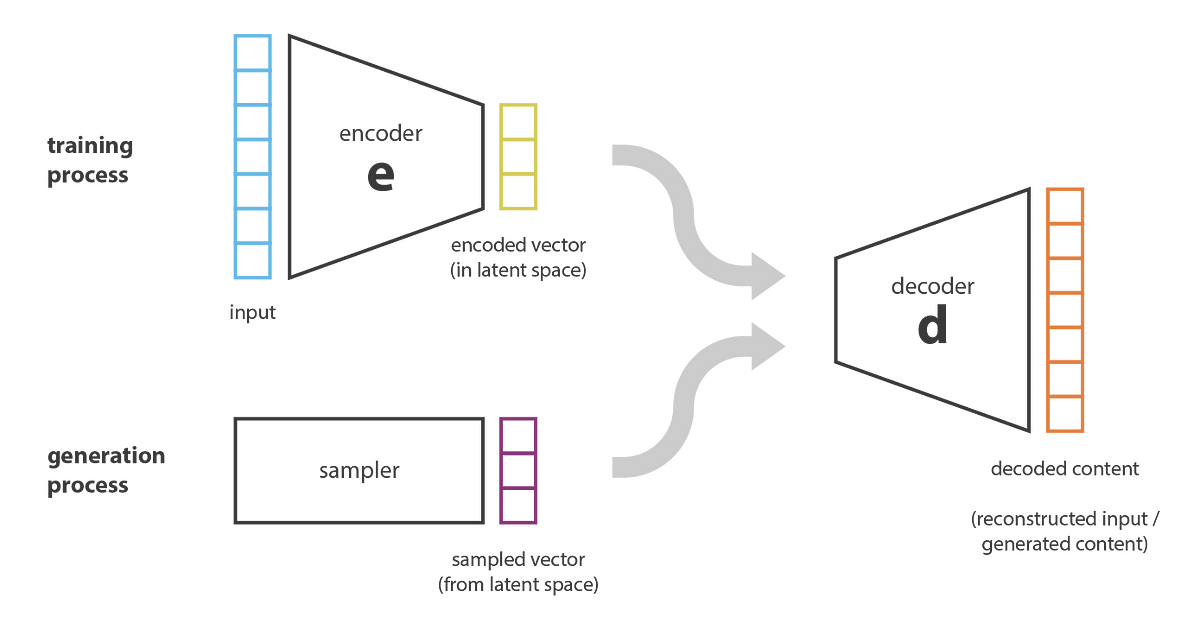 Figure (3a): Generative Adversarial Networks (course: AI Multiple) Figure (3b): Variational Autoencoders (course: Towards data science)
Figure (3a): Generative Adversarial Networks (course: AI Multiple) Figure (3b): Variational Autoencoders (course: Towards data science)
2. 3D Rendering-based methods
The basic workflow for 3D Rendering-based SD generation is fairly straightforward:
Prepare and procedurally generate 3D models of objects, place them in a simulated scene, set up the environment (camera viewpoint, lighting, etc.) and render synthetic images for training. Basically, creating a photorealistic virtual world and extracting images of them. When you have 3D rendered synthetic data, the 3D renderer will also do the annotation automatically for you.
While reaching out to a few synthetic data startups and companies, I found that majority of them rely on CGI or 3D rendering based methods for synthetic data generation. The reason for avoiding deep learning-based methods can be easily guessed: Firstly, it’s not easy to optimize GANs. Secondly, GANs come with issues of mode collapse. This means that your generator collapses which produce a limited variety of samples, ie. only a few categories of data are generated. This is undesirable. After all, bringing diversity and corner cases to training is the whole idea of using synthetic datasets. However, these companies use adversarial networks more for domain adaptation.
Benefits of synthetic data and why you must consider adopting them in your training and testing.
Here are a few reasons why you must adopt synthetic data for training and testing:
- Synthetic data alleviates the dataset bias. This is specifically important for human-related computer vision tasks like face recognition.
- Synthetic data is capable of covering corner cases in contexts where real data capture is not practical. Many at times the real datasets are insufficiently diverse. Synthetic data encompasses more use cases and modalities. This way your model is prepared to handle rarely occurring critical cases.
- Data collection and labelling is a laborious, costly and time-consuming task (For example: annotations for facial keypoint detection). You can achieve automatic pixel-perfect labelling for your dataset. This saves you a lot of time and speeds up your product’s time to market.
- It resolves privacy or legal issues that make the use of real data impossible or prohibitively hard. For example in medical and finance applications.
- At the rendering level, synthetic data generation can randomize lighting conditions, camera viewpoints, the orientation of objects, change image resolution, etc.
Brace yourself as we take a step further to take a look at a technique used to enhance or improve synthetic data. This technique plays an integral part in reducing Sim2Real gap in synthetic data. I’ll briefly describe what it is and leave a detailed explanation for another day.
- Domain Randomization In this technique, synthetic data is randomized and made more diverse by creating variations in the rendering or 3-D scene. This forces the network to learn to focus on the essential features of the image. An example of this technique is randomly placing distractor objects in 3D scenes.

Figure 3: Circled in red are the distractor objects (Source: https://arxiv.org/pdf/1804.06516.pdf)
Summary:
Here are a few startups and companies that I personally felt have done some impressive work in synthetic data for vision training — AI Reverie, Chooch AI, Datagen, Parallel Domain, Neurolabs, Synthesis AI, Zumo Labs
You can find a comprehensive list of synthetic data companies here. I haven’t had a chance to watch the demo of all the companies on the list. Check it out if you’re interested.
Hope this article helped you get insights into synthetic data generation and its use-cases. In the coming days, I’m hoping to work on some off the shelf tools and packages in the SD domain. I’ll keep you posted about that.
Thanks for Reading!